关于深度学习,这可能是你最容易读进去的科普贴了(三)

编者按:本文作者王川,投资人,中科大少年班校友,现居加州硅谷,个人微信号9935070,微博 @硅谷王川。36 氪经授权转载自其个人微信公众号 investguru。查看本系列文章点这里。
一
1992 年笔者在纽约州的罗切斯特大学选修计算机课的时候,学到这样一句话,印象极为深刻。
When in doubt, use brute force.
"如果遇到困惑(的问题), 就使用蛮力. "
此话出自当年 UNIX 系统的发明人之一 Ken Thompson。他的本意是,程序设计中,简单粗暴的计算方法,虽然可能计算量大,但是便于实现和维护,长期看,还是优于一些精巧但是复杂的计算手段。
这句话常令我遐想起,1943年七月苏联和德国在库尔斯克的坦克大决战。苏军八千多辆傻大黑粗的T-34 坦克,以损失三倍于对手的惨重代价,最终挫败德军三千多辆质量精良的虎式坦克集群。
 有哲人对蛮力有另外一个诠释:“ Quantity is Quality ”。
有哲人对蛮力有另外一个诠释:“ Quantity is Quality ”。
数量就是质量。向数量要质量。
九十年代,一个简单的神经网络数据培训的计算往往至少要花几天、甚至几周的时间。
这对于算法的改进调整和应用开发,都是一个巨大的瓶颈。
神经网络的研究,呼唤着蛮力,呼唤着来自计算速度、网络速度、内存容量、数据规模各个方面的、更强大的、指数增长的蛮力。
二
这个蛮力的基础,其实在1993年就埋下了种子。
 黄仁勋,1963年出生于台湾。1993年从斯坦福大学硕士毕业后不久,创立了 Nvidia。
黄仁勋,1963年出生于台湾。1993年从斯坦福大学硕士毕业后不久,创立了 Nvidia。
Nvidia 起家时,做的是图像处理的芯片,主要面对电脑游戏市场。1999 年Nvidia推销自己的 Geforce 256 芯片时,发明了 GPU (Graphics Processing Unit, 图像处理器)这个名词。
GPU 的主要任务,是要在最短时间内显示上百万、千万甚至更多的像素。这在电脑游戏中是最核心的需求。这个计算工作的核心特点,是要同时并行处理海量的数据。
GPU 在芯片层面的设计时,专门优化系统,用于处理大规模并行计算。
传统的 CPU (中央处理器) 芯片架构,关注点不在并行处理,一次只能同时做一两个加减法运算。 而GPU 在最底层的算术逻辑单元 (ALU, Arithmetic Logic Unit),是基于所谓的 Single Instruction Multiple Data ( 单指令多数据流)的架构,擅长对于大批量数据并行处理。
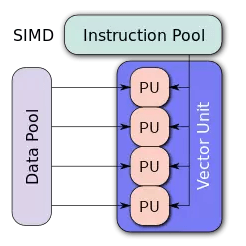 打个最简单的比方,如果有 1, 2, 3, .. 32 个数字,你需要对它们进行计算处理。传统的 CPU,32 个数字要一个个按顺序依次计算。
打个最简单的比方,如果有 1, 2, 3, .. 32 个数字,你需要对它们进行计算处理。传统的 CPU,32 个数字要一个个按顺序依次计算。
但是 GPU 在最低层的ALU,允许同时对 32个数字做批量处理。
一个 GPU,往往包含几百个 ALU, 并行计算能力极高。所以尽管 GPU 内核的时钟速度往往比 CPU的还要慢,但对大规模并行处理的计算工作,速度比 CPU 快许多。
而神经网络的计算工作,本质上就是大量的矩阵计算的操作,因此特别适合于使用 GPU。
三
这个速度有多快呢?Nvidia 480 GPU, 2010年的时候,一秒钟可以显示十六亿个三角形,一秒钟计算速度达 1.3 TFLOPS (万亿次浮点计算)。
而2015年出品的 Nvidia Titan X GPU, 一秒钟可以达到 6.1 TFLOPS , 接近2010年的五倍。其二手货的市价不到一千美元。
作为参照,人类的超级计算机,真正第一次突破一个 TFLOPS 的计算速度,实际上也就是1996年底,但其价格是几百万美元量级的。
2007年 Nvidia 推出名叫 CUDA 的并行计算软件开发接口,使开发者可以更方便的使用其 GPU开发应用软件。多家大学的研究者撰文表示,对于特定工作,NVIDIA GPU带来的相对于 Intel 的CPU 的计算速度提高,达到 100-300 倍。
Intel 技术人员2010年专门发表文章驳斥,大意是 Nvidia 实际上只比 intel 快 14倍,而不是传说中的 100 倍。
Nvidia 的 Andy Keane 评论: “老夫在芯片行业混了 26年了,从没见过一个竞争对手,在重要的行业会议上站起来宣布,你的技术 *** 只是 *** 比他们快14 倍”。
一个蛮力,一个来自 GPU 的计算蛮力,要在深度学习的应用中爆发了。