关于深度学习,这可能是你最容易读进去的科普贴了(四)
编者按:本文作者王川,投资人,中科大少年班校友,现居加州硅谷,个人微信号9935070,微博 @ 硅谷王川。36 氪经授权转载自其个人微信公众号 investguru。查看本系列文章点这里。
一
九十年代末,神经网络研究遇到的困境,除了慢,还是慢。
抛开计算速度的因素,传统神经网络的反向传播算法,捉虫时极为困难,一个根本的问题叫做所谓 vanishing gradient problem (梯度消失问题)。
这个问题在1991年,被德国学者 Sepp Hochreiter第一次清晰提出和阐明原因。
简单的说, 就是成本函数 (cost function)从输出层反向传播时, 每经过一层,梯度衰减速度极快, 学习速度变得极慢,神经网络很容易停滞于局部最优解而无法自拔。
这就像原始部落的小混混,山中无老虎时,在本地称王称霸很舒服。 但任何关于"外面的世界很精彩"的信息,在落后的层层传播机制中被噪音混淆淹没了。
小混混一辈子很开心, 没有意识到外面的世界有多大, 也从未想出去多看看。
二
支持向量机 (SVM) 技术在图像和语音识别方面的成功,使得神经网络的研究重新陷入低潮。
SVM 理论上更加严谨完备,结果重复性好, 上手简单, 得到主流学术界的追捧。
学术界的共识是: 多层神经网络的计算模型,实践效果不好,完全没有前途。 这是个死胡同。
这个情况到本世纪初,变得如此糟糕, 以至于任何论文送到学术期刊时,研究者都不敢用“神经网络”几个字,免得被粗暴拒绝。
2003年,Geoffrey Hinton, 还在多伦多大学,在神经网络的领域苦苦坚守。
一个五十六岁的穷教授, 搞了三十多年没有前途的研究,要四处绞尽脑汁,化缘申请研究经费。他不是卢瑟 (loser) , 谁还是卢瑟?
2003年在温哥华大都会酒店,以Hinton 为首的十五名来自各地的不同专业的科学家,和加拿大先进研究院 (Canadan Institue oF Advanced Research, 简称 CIFAR) 的基金管理负责人,Melvin Silverman 交谈。
Silverman 问大家,为什么 CIFAR 要支持他们的研究项目。
计算神经科学研究者,Sebastian Sung (现为普林斯顿大学教授),回答道,“喔,因为我们有点古怪。如果CIFAR 要跳出自己的舒适区,寻找一个高风险,极具探索性的团体,就应当资助我们了!”
最终CIFAR 同意从2004年开始资助这个团体十年,总额一千万加元。CIFAR 成为当时,世界上唯一支持神经网络研究的机构。
不夸张地说,如果没有 2004年 CIFAR 的资金支持,人类在人工智能的研究上可能还会在黑暗中多摸索几年。
Hinton 拿到资金支持不久,做的第一件事,就是先换个牌坊。
两千多年前的刘三, 改了名换了姓,叫什么 "汉高祖"。鉴于"神经网络"口碑不好,也被 Hinton 改了名,换了姓,叫 "深度学习" (Deep Learning) 了。
Hinton 的同事,此后时不时会听到他突然在办公室大叫,"我知道人脑是如何工作的了!"。
三
2006年,Hinton 和合作者发表论文,"A fast algorithm for deep belief nets" (深信度网络的一种快速算法)。
在这篇论文里,Hinton 在算法上的核心,是借用了统计力学里的"玻尔兹曼分布"的概念 (一个微粒在某个状态的几率,和那个状态的能量的指数成反比,和它的温度的倒数之指数成反比),使用所谓的"限制玻尔兹曼机" (RBM)来学习。
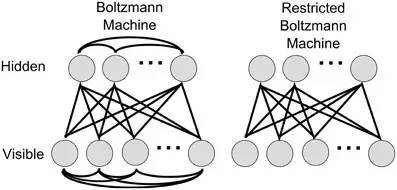
RBM 引入了统计力学常用的概率工具。而在七十年代,概率和不确定性恰恰是主流的人工智能的研究者极为痛恨的。
RBM 相当于一个两层网络,同一层神经元之间不可连接 (所以叫 "限制"),可以对神经网络实现“没有监督的训练”(unsupervised training)。深信度网络就是几层 RBM 叠加在一起。
略掉技术细节,RBM 可以从输入数据中进行预先训练,自己寻找发现重要的特征,对神经网络连接的权重进行有效的初始化。这属于一种叫做特征提取器 (feature extractor)的神经网络,也称自动编码器 (autoencoder)。
经过 RBM 预先训练初始化后的神经网络,再用反向传播算法微调,效果就好多了。
Hinton 后来指出,深度学习的突破,除了计算蛮力的大幅度提高以外聪明有效地对网络链接权重的初始化也是一个重要原因。
Hinton 的论文里,经过六万个MNIST 数据库的图像培训后,对于一万个测试图像的识别错误率最低降到了只有 1.25%。
虽然这还不足以让主流学术界改变观点,但深度学习的发展已经见到一丝曙光。