首次公开:京东数科强一致、高性能分布式事务中间件 JDTX
做积极的人,而不是积极废人!
在分布式数据库、云原生数据库、NewSQL 等名词在数据库领域层出不穷的当今,变革——在这个相对稳定的领域已愈加不可避免。相比于完全革新,渐进式增强的方案在拥有厚重沉淀的行业则更受青睐。
同所有分布式领域的解决方案相同,分而治之的透明化数据分片方案,是新一代数据库解决海量数据的核心理念。水平拆分使得分布式事务的重要性,较之垂直拆分的业务系统进一步提升。另外,弹性扩(缩)容、HTAP 等概念也是新一代数据库的关注重点。京东数科开源的 Apache ShardingSphere 在数据分片方面已逐渐成熟,在此场景之上开发的分布式事务中间件 JDTX 与之共同组成了分布式数据库的内核拼图。
JDTX 是由京东数科的数据研发团队倾力打造的分布式事务中间件。本次分享是 JDTX 首次公开出现在大众视野面前,分享内容涵盖 JDTX 的核心设计理念及相关的技术实现难点,希望能为打造分布式事务解决方案的团队提供一些思路
数据库事务需要满足 ACID(原子性、一致性、隔离性、持久性)4 个特性。
在单一数据节点中,事务仅限于对单一数据库资源的访问控制,称之为本地事务。几乎所有的成熟的关系型数据库都提供了对本地事务的原生支持。但是在基于微服务的分布式应用环境下,越来越多的应用场景要求对多个服务的访问及其相对应的多个数据库资源能纳入到同一个事务当中,分布式事务应运而生。
关系型数据库虽然对本地事务提供了完美的 ACID 原生支持。但在分布式的场景下,它却成为系统性能的桎梏。如何让数据库在分布式场景下满足 ACID 的特性或找寻相应的替代方案,是分布式事务的重点工作。
本地事务
在不开启任何分布式事务管理器的前提下,让每个数据节点各自管理自己的事务。它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。本地事务在性能方面无任何损耗,但在强一致性以及最终一致性方面则力不从心。
两阶段提交
XA 协议最早的分布式事务模型是由 X/Open 国际联盟提出的 X/Open Distributed Transaction Processing(DTP)模型,简称 XA 协议。
基于 XA 协议实现的分布式事务对业务侵入很小。它最大的优势就是对使用方透明,用户可以像使用本地事务一样使用基于 XA 协议的分布式事务。XA 协议能够严格保障事务 ACID 特性。
严格保障事务 ACID 特性是一把双刃剑。事务执行在过程中需要将所需资源全部锁定,它更加适用于执行时间确定的短事务。对于长事务来说,整个事务进行期间对数据的独占,将导致对热点数据依赖的业务系统并发性能衰退明显。因此,在高并发的性能至上场景中,基于 XA 协议两阶段提交类型的分布式事务并不是最佳选择。
柔性事务
如果将实现了 ACID 的事务要素的事务称为刚性事务的话,那么基于 BASE 事务要素的事务则称为柔性事务。BASE 是基本可用、柔性状态和最终一致性这 3 个要素的缩写。
在 ACID 事务中对一致性和隔离性的要求很高,在事务执行过程中,必须将所有的资源占用。柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。通过放宽对强一致性和隔离性的要求,只要求当整个事务最终结束的时候,数据是一致的。而在事务执行期间,任何读取操作得到的数据都有可能被改变。这种弱一致性的设计可以用来换取系统吞吐量的提升。Saga 和 TCC 都是典型的柔性事务实现方案。
基于 ACID 的两阶段事务和基于 BASE 的最终一致性事务都不是银弹,可通过下表详细对比它们之间的区别。
| 两阶段提交 | 柔性事务 | |
|---|---|---|
| 业务改造 | 实现相关接口 | |
| 最终一致 | ||
| 业务方保证 | ||
| 并发性能 | 严重衰退 | 略微衰退 |
| 适合场景 | 短事务 & 低并发 | 长事务 & 高并发 |
缺乏并发度保障的两阶段事务不能称之为完善的分布式事务解决方案;而缺乏对 ACID 原义支持的柔性事务都甚至不能称之为数据库事务,它更适合服务层的事务处理。
放眼当前,实难找到无需权衡即可放之四海而皆准的分布式事务解决方案。
JDTX 的分布式事务解决方案
JDTX 的设计目标是强一致(支持 ACID 的事务原义)、高性能(甚至强于本地事务)、1PC(完全摒弃两阶段提交和两阶段锁)的完全分布式事务中间件,目前可用于关系型数据库。它采用完全开放 SPI 的设计方式,提供与 NoSQL 对接的可能,能够将多元异构数据维持在同一事务中。
设计理念
首先通过一张架构图来直观的了解一下 JDTX 的构成。
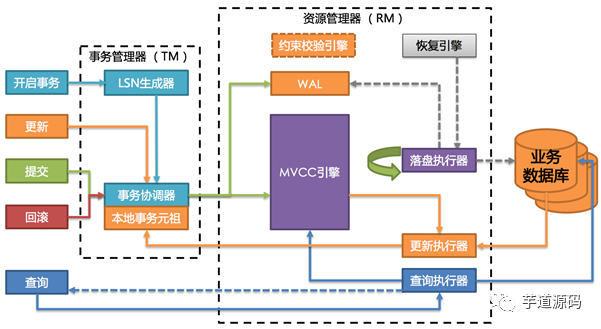
JDTX 由事务管理器(TM)和资源管理器(RM)组成。
事务管理器用于生成全局单调递增的事务日志序列号(LSN),事务的提交和回滚等核心流程处理,以及未提交事务的本地元祖(Tuple)持有。
资源管理器用于管理活跃事务数据。JDTX 的设计特点是将在事务中的数据(称之为活跃数据)和不在事务中的数据(称之为落盘数据)分离。活跃数据在落盘至预写日志系统(WAL)之后,并将数据保存至自研的多版本快照(MVCC)内存引擎中。落盘数据则是通过异步刷盘的方式,将 MVCC 引擎中的数据以流量可控的方式同步至最终的存储介质中(如:关系型数据库)。
事务内查询会将落盘数据和活跃数据合并,并根据当前事务的隔离级别获取出符合当前事务可见性的数据版本。
方案亮点
无损事务方案
JDTX 采用 WAL + MVCC 引擎的方式实现了事务的 ACID 原义。
原子性 & 一致性支持
JDTX 的 MVCC 引擎可以看做是一个集中式缓存,可以将两阶段提交简化至一阶段提交。维持单一节点中数据的原子性和一致性,即将分布式事务的范畴缩减到本地事务的范畴。
MVCC 引擎可以通过分片 + 主从同步的方式维持水平扩展和高可用的能力。JDTX 保证所有对事务数据的访问都通过 MVCC 引擎的活跃数据 + 最终数据端的落盘数据的合并的方式,以保证数据的原子性和一致性。
隔离性支持
JDTX 以多版本快照的方式实现事务隔离性。目前完整的支持 4 种标准隔离级别中的读已提交和可重复读,已经可以满足绝大部分需求。
持久性支持
JDTX 将事务的活跃数据在存入 MVCC 引擎之前先落盘至 WAL 引擎,以保证服务器崩溃,内存数据丢失时,活跃数据依然能够从 WAL 引擎中完全恢复。
JDTX 采用将活跃数据异步刷盘至数据库的方式极大的提高了数据写入的性能上限。它的性能瓶颈从数据库写入耗时转移到了落盘至 WAL 引擎和存储至 MVCC 引擎的耗时。
与数据库的 WAL 系统类似,JDTX 的 WAL 也采用日志顺序追加的方式,因此可以简单的理解为 JDTX 的 WAL 耗时 = 数据库系统的 WAL 耗时。而 MVCC 缓存则采用哈希数据结构,其写入耗时小于需要维护 BTree 索引的数据库写入耗时。因此,采用 JDTX 的事务方案,其数据更新性能甚至强于不开启事务。
另外,JDTX 采取了无 UNDO 日志的事务回滚策略。未提交的数据并不会进入 MVCC 引擎,而是被事务管理器本地持有。因此,只要清理掉未提交数据即可完成事务回滚。无 UNDO 日志的设计进一步的提升了事务处理的性能。
WAL 引擎和 MVCC 引擎均采用分片 + 主备的方式,以保证 JDTX 不会产生单点故障。在 MVCC 引擎完全不可用的情况下,可通过恢复模式将 WAL 中的数据同步至数据库,以保证数据的完整性。
跨多元数据库事务
JDTX 将事务活跃数据和落盘数据分离的设计方案,使其落盘数据存储端无任何限制。所有的事务活跃数据都会通过异步的落盘执行器存储至后端数据库,因此后端是否为同构数据库,其实并无影响。
使用 JDTX 能够保证跨多元存储端(如:MySQL、PostgreSQL 甚至是 MongoDB、Redis 等 NoSQL)的分布式事务维持在同一事务语义之中。
实现难点
MVCC 内核
事务隔离级别有两种常见的实现方案,即锁实现和 MVCC 实现。除了 Infomix 等少数数据库,大部分关系型数据库均采用 MVCC 实现。
读未提交、读已提交、可重复读和可序列化这 4 种事务隔离级别的标准,是 ANSI 所定义的基于锁实现的方式。事务的并行度随着隔离级别的增加而衰减,除了并发度最低的可序列化,其他隔离级别都伴随着对一致性的权衡和牺牲。
下表是基于锁实现的隔离级别对照表。
| 隔离级别 | 不可重复读 |
|---|---|
| 读未提交 | |
| 读已提交 | |
| 可重复读 | |
| 可序列化 |
通过 MVCC 实现的隔离级别实际上只有 SI(快照隔离)和 SSI(可序列化快照隔离)这 2 种。SI 和 SSI 与 ANSI 的 4 种隔离级别并不能完全对照。其中的读未提交,与读已提交在 MVCC 的实现中性能并无差别,可以忽略不计。因此 SI 可以对应为读已提交和可重复读这 2 种隔离级别。实际上,即使是幻读,在 SI 隔离级别中也是不会出现的。
由于快照并发控制并不能真正意义上保证事务是“可串行化”的,所以事务间的并发操作依旧有可能引发数据异常现象。但这里的异常不同于之前提到的脏读、丢失更新的异常,而是一种业务数据间逻辑语义层面的异常,也可以说是由于未能满足数据间的语义约束而产生的异常。这被称之为写偏序(Write skew),它的检测可依据并发事务间读写依赖的多版本可串行化图(The multiversion serialization graph)来实现,即 SSI 隔离级别。
下表是基于 MVCC 实现的隔离级别对照表。
| 隔离级别 | 不可重复读 | |||
|---|---|---|---|---|
| 读未提交 | 无需实现 | 无需实现 | 无需实现 | 无需实现 |
| 读已提交 | ||||
| 可重复读 | ||||
| 可序列化 |
自研 MVCC 引擎是 JDTX 的主要难点之一。JDTX 采用与 PostgreSQL 类似的 MVCC 实现方案,通过 xmin 和 xmax 标记事务快照范围,并在 MVCC 引擎中保存每个数据元祖(Tuple)的 xmin 和 xmax 的事务信息。同一数据的多版本以链表的数据结构存储,通过其 xmin 和 xmax 来获取数据的版本在当前事务快照中的可见性。
由于 MySQL 也并未实现 SSI 隔离级别,因此目前的 JDTX 只是实现了 SI 隔离级别,还并未实现 SSI 隔离级别。
MVCC 数据的清理(vacuum)是另一技术难点。过长的事务会导致 MVCC 版本过多,导致占用大量存储空间。尤其是 JDTX 是通过内存来存储 MVCC 的活跃数据,因此对内存空间的释放则更加敏感。由于 JDTX 的异步落盘机制,因此除了 MVCC 标准的垃圾回收逻辑之外,判断数据是否落盘成为清理逻辑的额外规则。
SQL 查询引擎
通过 SQL 查询事务的活跃数据,是 JDTX 的另一个技术实现难点。MVCC 引擎并非关系型数据库,并不能通过识别 SQL 来查询相关数据。JDTX 则通过之前 Apache ShardingSphere 所积累的 SQL 解析模块及其抽象语法树(AST)来实现对 SQL 的理解,以及查询基于内存的 MVCC 引擎中的数据。
对于 SPJ(select-project-join)的 OLTP 类型 SQL,可以从 SQL 的查询结果中获取数据主键。JDTX 将落盘数据从后端数据库中取出作为最终展现数据的基础,并在此之上从 MVCC 引擎中查询出当前事务可见的活跃数据,并对其结果进行归并。换句话说,每次事务内查询都是由落盘数据 + 活跃数据归并而成。归并引擎部分参照了 LSM Tree 的设计思想。
对于非 SPJ 的 OLAP 类型 SQL,JDTX 则采用另外的查询方式。基于聚合函数和分组的 SQL 无法通过主键直接将后端数据库中的落盘数据和 MVCC 引擎中的键值数据直接匹配,因此采用以 MVCC 引擎中数据为主,并将 SQL 改写为剔除活跃数据主键的新 SQL,再从后端数据库中查询无重复的聚合数据进行归并。
使用限制
分布式无银弹,这是架构师们对现有的分布式系统比较公认的看法。虽然 JDTX 具备了很多优点,但仍然有一些使用限制。它的使用限制主要有以下 3 点。
-
需要通过 JDTX 访问数据库。JDTX 通过其 MVCC 引擎控制事务的原子性、一致性和隔离性,并通过 WAL 控制事务的持久性。因此在使用 JDTX 的系统中,跨过事务中间件直接查询数据库,是得不到正确的事务数据的,修改数据库则会导致数据紊乱。
-
SQL 支持需要持续完善。查询 MVCC 引擎的 SQL 方言兼容则需要持续提升。相对于无损的 ACID 事务原义支持所带来的优势,SQL 兼容度的下降,是 JDTX 带来的权衡。
-
不支持无主键数据。JDTX 需要通过主键来合并 MVCC 引擎和数据库中的数据。因此无法处理没有主键的记录。
JDTX 与 Apache ShardingSphere
通过 Apache ShardingSphere 提供的 JDBC 接入端,可以使 JDTX 无缝的对接至 Java 应用。除了 JDBC 接入端,Apache ShardingSphere 也提供了基于 MySQL 和 PostgreSQL 的 Proxy 接入端,使 JDTX 像一个单独的数据库一样提供分布式事务的服务。Apache ShardingSphere 将在未来将接入端剥离,使 JDTX 独立使用成为可能。
Apache ShardingSphere 提供了分布式事务的统一 SPI。JDTX 通过实现 ShardingSphere 提供的 SPI,可以很轻松的融入 Apache ShardingSphere 生态。结合 Apache ShardingSphere 与 JDTX,可以将数据分片与分布式事务无缝结合。
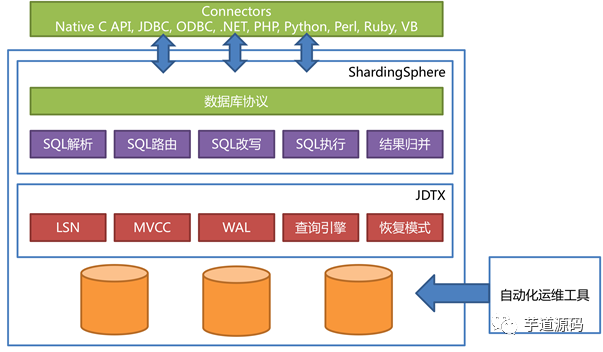
独立使用 Apache ShardingSphere 或 JDTX,可以灵活解耦,高度定制,可以看做是基础组件的乐高积木。而将其联合使用,则能够产生化学变化,甚至使它们具备组成分布式数据库基础设施的能力。架设在产品最前端的 Apache ShardingSphere 用于 SQL 解析、数据库协议和数据分片;位于中层的 JDTX 用于通过键值对和 MVCC 的方式处理事务活跃数据;最底层的数据库则仅作为最终的数据存储端。下图是 ShardingSphere + JDTX 的架构图。
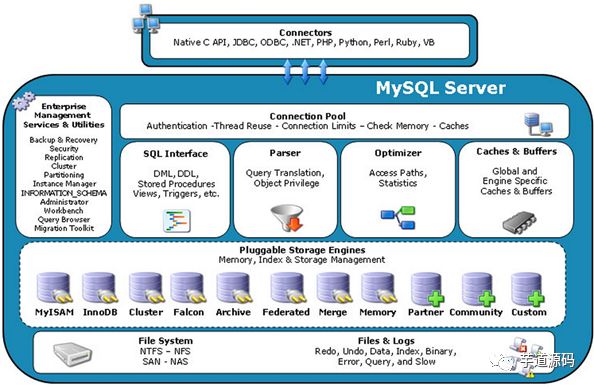
最后附上 MySQL 架构图,请读者自行体会其相似之处。
JDTX 的后续规划
JDTX 的自身目标是力争将其打造成为一个分布式事务的标准解决方案。在事务核心流程、MVCC 引擎、WAL 引擎、高可用等核心功能打磨成熟后,JDTX 会将主要精力投放在以下几个方面:
-
提升 SQL 语句兼容性以及多元数据库支持;
-
实现 SSI 隔离级别,提供完整的 MVCC 隔离级别解决方案;
-
完善管理端和监控端。
除了 JDTX 中间件自身,它也将与 ShardingSphere 等其他数据库中间件更加一体化的提供分布式数据库级别的服务;并将与 Kubernetes 等云原生平台更加深度整合,为云原生数据库提供服务。
作者介绍
,京东数科数据研发负责人, Apache ShardingSphere 发起人 & PPMC,JDTX 负责人。
热爱开源,主导开源项目 ShardingSphere(原名 Sharding-JDBC) 和 Elastic-Job。擅长以 Java 为主分布式架构,推崇优雅代码,对如何写出具有展现力的代码有较多研究。
目前主要精力投入在将 ShardingSphere 和 JDTX 打造为业界一流的金融级数据解决方案之上。ShardingSphere 已经进入 Apache 孵化器,是京东集团首个进入 Apache 基金会的开源项目,也是 Apache 基金会首个分布式数据库中间件。
GitHub: https://github.com/terrymanu, 随时欢迎技术交流和指正。