几乎所有的小伙伴都可以随口说几句关于创建索引的优缺点,也知道什么时候创建索引能够提高我们的查询性能,什么时候索引会更新,但是你有没有注意到,即使你设置了索引,有些时候索引他是不会生效的!这不仅考察了大家对索引的了解程度,还要让大家在使用的时候能够正确的使用。以下介绍了一些可能会造成索引失效的特殊情况,希望大家在平时开发和面试的时候能够注意到!
一、如何判断数据库索引是否生效
首先在接着探讨之前,我们先说一下,如何判断数据库的索引是否生效!相信大家应该猜到了,就是explain!explain显示了MySQL如何使用索引来处理select语句以及连接表。他可以帮助选择更好的索引和写出更优化的查询语句。
例如我们有一张表user,为name列创建索引name_index,如下所示: 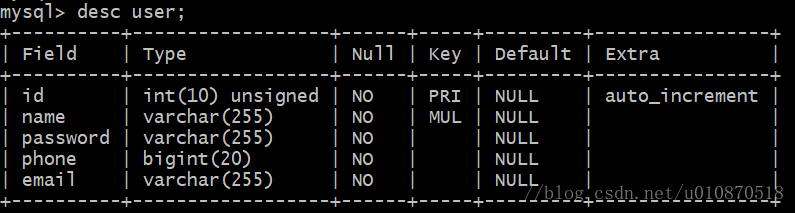 使用explain分析语句如下:
使用explain分析语句如下:  可以看到,使用explain显示了很多列,各个关键字的含义如下:
可以看到,使用explain显示了很多列,各个关键字的含义如下:
-
table:顾名思义,显示这一行的数据是关于哪张表的;
-
type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为:const、eq_reg、ref、range、indexhe和ALL;
-
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从where语句中选择一个合适的语句;
-
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MySQL会选择优化不足的索引。这种情况下,可以在Select语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MySQL忽略索引;
-
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好;
-
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数;
-
rows:MySQL认为必须检查的用来返回请求数据的行数;
-
Extra:关于MySQL如何解析查询的额外信息。
具体的各个列所能表示的值以及含义可以参考MySQL官方文档介绍,地址:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
二、哪些场景会造成索引生效
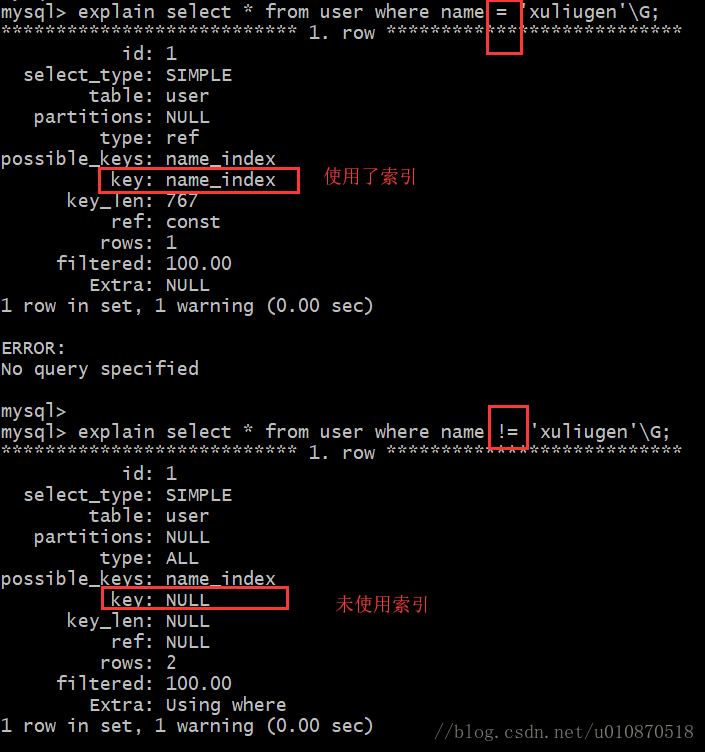
1、应尽量避免在 where 子句中使用 != 或 <> 操作符
否则引擎将放弃使用索引而进行全表扫描;
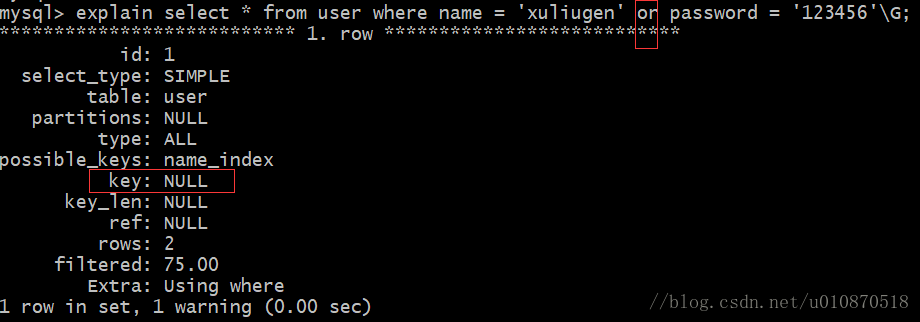
2、尽量避免在 where 子句中使用 or 来连接条件
否则将导致引擎放弃使用索引而进行全表扫描,即使其中有条件带索引也不会使用,这也是为什么尽量少用 or 的原因;
3、对于多列索引,不是使用的第一部分,则不会使用索引;
这句话某种程度上有问题,详细请参考:本文《第三节:最左前缀原则》
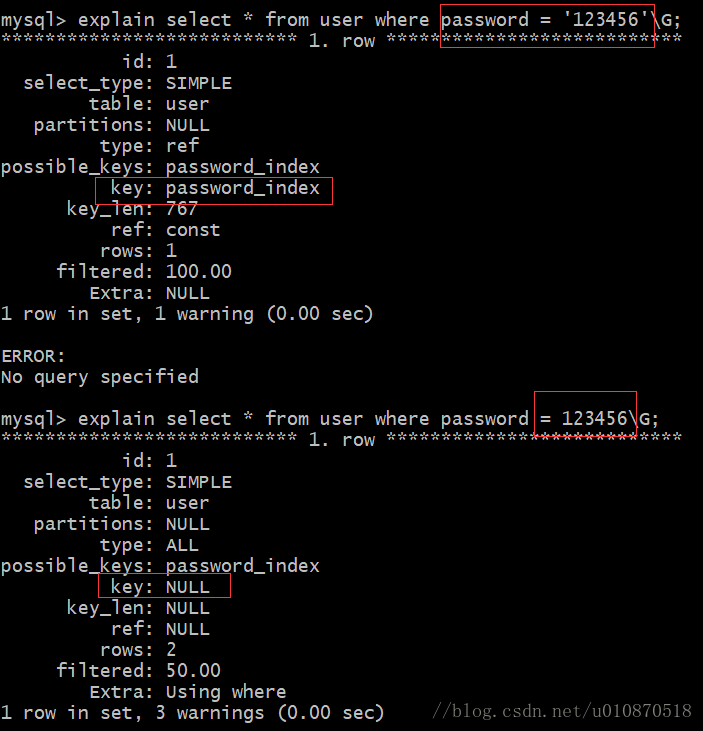
4、如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不会使用索引;
5、like的模糊查询以 % 开头,索引失效;
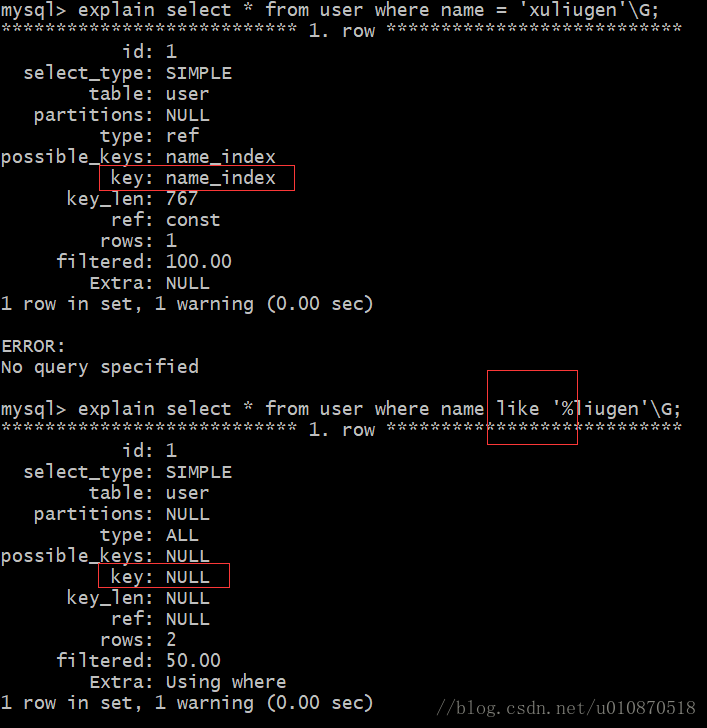 但是非前导模糊查询则可以:
但是非前导模糊查询则可以:
select * from user where name like xuliu%';
6、应尽量在 where 子句中对字段进行表达式操作
这将导致引擎放弃使用索引而进行全表扫描;
select id from t where num/2 = 100
应改为:
select id from t where num = 100*2;
7、应尽量在 where 子句中对字段进行函数操作
这将导致引擎放弃使用索引而进行全表扫描;
select id from t where substring(name,1,3) = 'abc' – name;
以abc开头的,应改成:
select id from t where name like ‘abc%’
select id from t where datediff(day, createdate, '2005-11-30') = 0 – '2005-11-30';
应改为:
select id from t where createdate >= '2005-11-30' and createdate < '2005-12-1';
8、不要在 where 子句中的 “=” 左边进行函数、算术运算或其他表达式运算
否则系统将可能无法正确使用索引;
9、如果MySQL估计使用全表扫描要比使用索引快,则不使用索引;
10、不适合键值较少的列(重复数据较多的列)
假如索引列TYPE有5个键值,如果有1万条数据,那么 WHERE TYPE = 1将访问表中的2000个数据块。再加上访问索引块,一共要访问大于200个的数据块。如果全表扫描,假设10条数据一个数据块,那么只需访问1000个数据块,既然全表扫描访问的数据块少一些,肯定就不会利用索引了。
三、最左前缀原则
最左前缀原则:顾名思义是最左优先,以最左边的为起点任何连续的索引都能匹配上。
(1)如果第一个字段是范围查询需要单独建一个索引;
(2)在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边;
当创建(a,b,c)复合索引时,想要索引生效的话,只能使用 a和ab、ac和abc三种组合!
实例:以下是常见的几个查询:
mysql>SELECT `a`,`b`,`c` FROM A WHERE `a`='a1' ; //索引生效 mysql>SELECT `a`,`b`,`c` FROM A WHERE `b`='b2' AND `c`='c2'; //索引失效 mysql>SELECT `a`,`b`,`c` FROM A WHERE `a`='a3' AND `c`='c3'; //索引生效,实际上值使用了索引a
扩展:想要索引最大化的使用需要至少建几个索引?
答:需要建立复合索引:bc
3.1、三个字段联合索引测试:
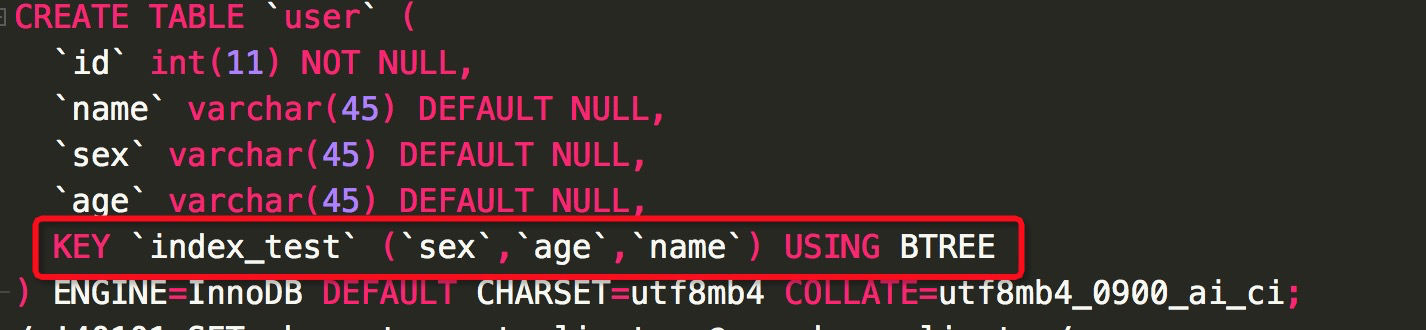 联合索引的顺序为:sex,age,name
联合索引的顺序为:sex,age,name
SELECT * FROM user where sex="3"; #使用索引 SELECT * FROM user where age="4"; #未使用索引 SELECT * FROM user where name="2"; #未使用索引 SELECT * FROM user where sex="2" and age="3"; #使用索引 SELECT * FROM user where sex="2" and age="3" and name="4"; #使用索引 SELECT * FROM user where age="3" and name="4"; #未使用索引 SELECT * FROM user where sex="2" and name="4"; #使用索引 #这个在3.2最后边解释,为什么 explain SELECT * FROM index_demo.user where age="2" and sex="3"; #使用索引
值得注意的是,where sex=“2” and name=“4” 这个相当于只有sex使用到了索引的,
 和where sex=“2” and age=“3” and name="4"的区别:
和where sex=“2” and age=“3” and name="4"的区别:

3.2、如果索引字段有两个
如果索引有两个字段:sex,age
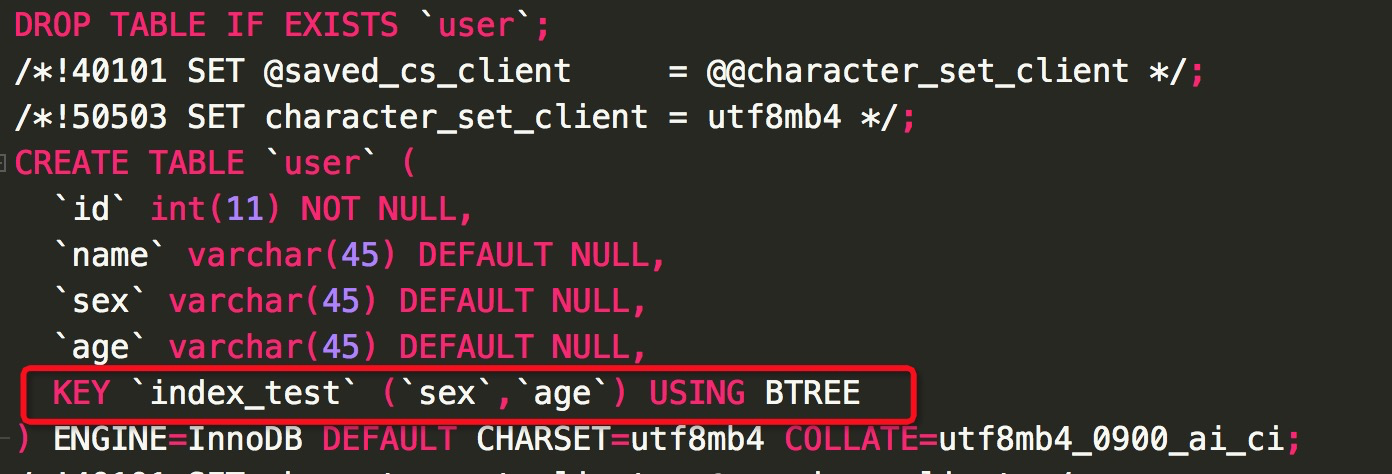
explain SELECT * FROM index_demo.user where sex="3"; #使用索引 explain SELECT * FROM index_demo.user where age="4"; #未使用索引 explain SELECT * FROM index_demo.user where sex="2" and age="3"; #使用索引 explain SELECT * FROM index_demo.user where age="3" and sex="4"; #使用索引

 where sex=“2” and age=“3”;和where sex=“2” and age=“3”;
where sex=“2” and age=“3”;和where sex=“2” and age=“3”;
这两个都是用了索引的,这是mysql查询优化器,mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,所以mysql查询优化器会最终以这种顺序进行查询执行。
然后回到刚才的3.1中三个索引的时候:sex,age,name
explain SELECT * FROM index_demo.user where age="2" and sex="3"; #使用索引
这条语句竟然使用索引了  可以看出他是使用索引了,因为对于三个索引的时候,只要是前两个,存在,不论顺序是什么都是会使用索引的,这里主要是mysql查询优化器起的作用了;
可以看出他是使用索引了,因为对于三个索引的时候,只要是前两个,存在,不论顺序是什么都是会使用索引的,这里主要是mysql查询优化器起的作用了;
参考文章:
1、http://blog.csdn.net/qq_33774822/article/details/61197420